Filtre de données non structurées
Pour en savoir plus sur les filtres en général, consulter l'article Comprendre les Filtres.
Utilisez ce filtre chaque fois que le déclencheur reçoit des données non structurées, telles que des documents et rapports exportés d'anciens systèmes, de communication interceptée entre deux périphériques et d'une capture d'un flux d'impression. Le filtre vous permet d'extraire les champs individuels, les champs répétables dans les sous-zones, et même les paires nom-valeur.
Pour des exemples de données de texte structuré, voir les articles Données existantes , CSV Composé et Fichiers binaires .
|
Définition de la structure
Éléments à utiliser pour configurer le filtre :
-
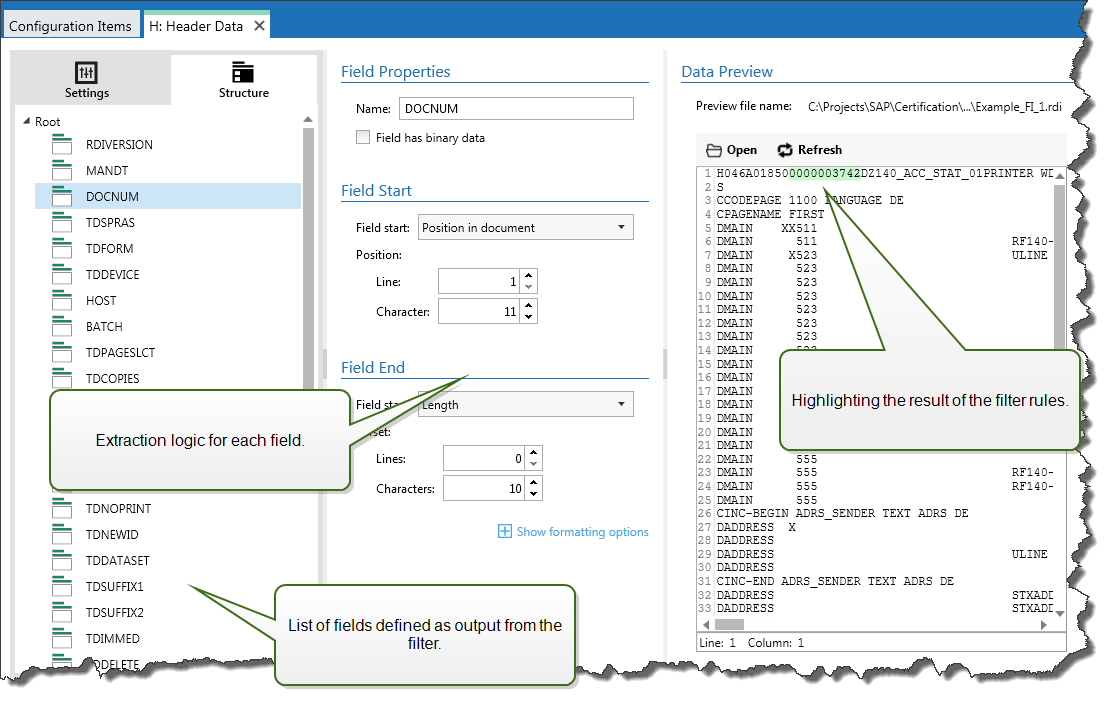
Champ: Spécifie l'emplacement des données de champ entre le début et la fin du champ. Il y a différentes options pour définir l'emplacement du champ, du codage en dur au placement relatif. Il faut relier les champs définis aux variables respectives dans l'action Utiliser le Filtre de Données . Pour plus d'informations, voir la section Définition des champs.
-
Sous-zone : Spécifie l'emplacement des données répétables. Chaque sous-zone définit au moins un bloc de données, qui à son tour contiendra des données pour les étiquettes. Il peut y avoir des sous-zones définies dans les sous-zones, permettant la définition de structures complexes. Des champs peuvent être définis dans chaque bloc de données. Il faut relier les champs définis aux variables respectives dans l'action. Pour chaque sous-zone, Automation définit un nouveau niveau d'espace réservé dans l'action Utiliser le Filtre de Données, permettant de mapper les variables aux champs de ce niveau. Pour plus d'informations, voir la section Définition des sous-zones .
-
Zone d'affectation : Spécifie l'emplacement des données répétables contenant les paires nom-valeur. Automation lit les noms des champs et leurs valeurs simultanément. Automation effectue aussi automatiquement le mappage aux variables. Utiliser cette méthode pour adapter le filtre aux données d'entrée variables pour éliminer le temps de maintenance. Vous pouvez définir la zone d'affectation au niveau racine du document ou dans la sous-zone. Pour plus d'informations, voir la section Définition des zones d'affectation .
La section Aperçu de données simplifie la configuration. Le résultat des filtres définis est mis en évidence dans la zone d'aperçu à chaque changement de configuration. Vous pouvez visualiser les données extraites pour chaque règle.
Ce champ peut être défini au niveau racine comme champ du document. Les champs peuvent être définis dans un bloc de données. Les paires nom-valeur peuvent être définies dans la zone d'affectation.

|
Général
Cette section définit les propriétés générales du filtre de données non structurées.
-
Nom : Spécifie le nom du filtre. Utiliser un nom descriptif qui identifie le rôle d'un filtre dans une configuration. Il est modifiable à tout moment.
-
Description : Vous permet de décrire l'objectif de ce filtre. Vous pouvez l'utiliser pour écrire une courte description de la fonction du filtre.
-
Encodage : Spécifie l'encodage des données avec lesquelles ce filtre travaille.
-
Ignorer les lignes vides dans les blocs de données : Spécifie de ne pas signaler d'erreur si le filtre extrait des valeurs de champs vides des blocs de données.